Tokenizer
Tokenizer er tilreiðari fyrir íslenskan texta.
Hvað er tilreiðari?
Tilreiðari breytir venjulegum texta í tókastraum, þar sem hver tóki er stakt orð, greinarmerki, tala/upphæð, dags-/tímasetning, netfang, vefslóð, o.s.frv. Hann skiptir straumnum einnig í setningar, með tilliti til jaðartilvika eins og t.d. skammstafana og dagsetninga í miðjum setningum.

Tilreiðing er nauðsynlegt skref í forvinnslu texta fyrir frekari máltæknivinnslu. Hún getur verið grunn eða djúp. Grunntilreiðsla skilar setningum þar sem hver tóki er aðskilinn með bili. Djúptilreiðsla gefur tókahluti (e. token objects) markaða með gerð tóka og öðrum upplýsingum dregnum úr tókanum.
Notkun:
Tólið er aðgengilegt á PyPI (The Python Package Index) undir nafninu tokenizer og má sækja það með skipanalínutólinu pip:
pip install tokenizer
tokenize [-h] [--csv | --json] [-s] [-m] [-p] [-n] [-o] [-g] [-e] [-c] [-k HANDLE_KLUDGY_ORDINALS] [infile] [outfile]
Tólið má stilla á ýmsa vegu, og lesa má um þær stillingar með skipuninni tokenize -h eða hér undir “Command line tool”.
Ef nota skal textaskrá þarf hún að vera í UTF-8 kóðun.
Einnig er hægt að nota einingu í Python kóða, sjá nánar undir “Python module”.
Dæmi:
Einfalt prufudæmi er að nota echo og pípu til að senda texta í tólið:

Þetta er grunntilreiðsla.
Hægt er að nota textaskrár fyrir inntak og úttak:

Fyrir djúptilreiðslu þarf að stilla form úttaksskrár á csv eða json:
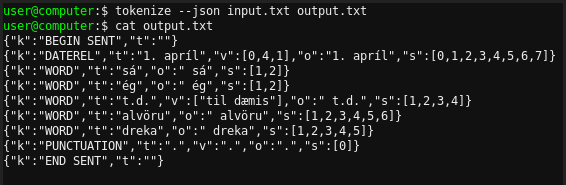
Eins og sjá má eru mismunandi tókar markaðir á ólíkan hátt, t.d. dagsetning sem "DATAREL" og greinarmerki sem "PUNCTUATION".
Tenglar:
Þorsteinsson, Vilhjálmur, 2020, Tokenizer for Icelandic text, CLARIN-IS, http://hdl.handle.net/20.500.12537/65. Tokenizer. GitLab